My Hypermind Arising Intelligence Forecasts and Reflections

Context
The Arising Intelligence tournament is being run on Hypermind, consisting of "questions about progress toward general artificial intelligence". There are versions of each question resolving in each year from 2022 to 2025. There are $30,000 worth of prizes spread across the 4 years, increasing from $3,000 to $12,000 between 2022 and 2025.
Selected 2025 forecasts
Note that as discussed in the Reflections section, Hypermind's interface for inputting distributions is fairly inflexible. I'd like to make all these forecasts substantially wider, so mostly pay attention to the median.
US vs. China experiment size
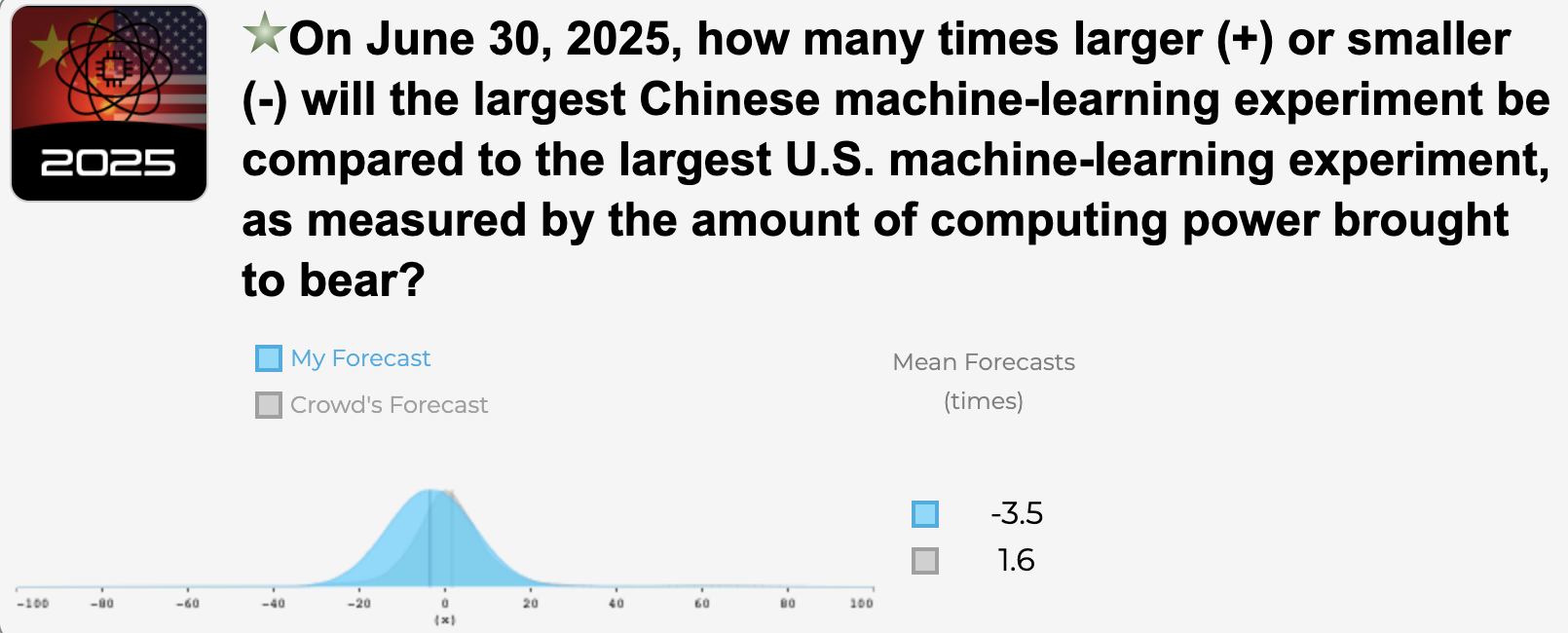
My median is that the US's ML experiments will remain larger than China's (though not by as much; the current multiplier is -6x), while the crowd expects China's to be larger by 2025.
Most computing power from non-Chinese non-giant
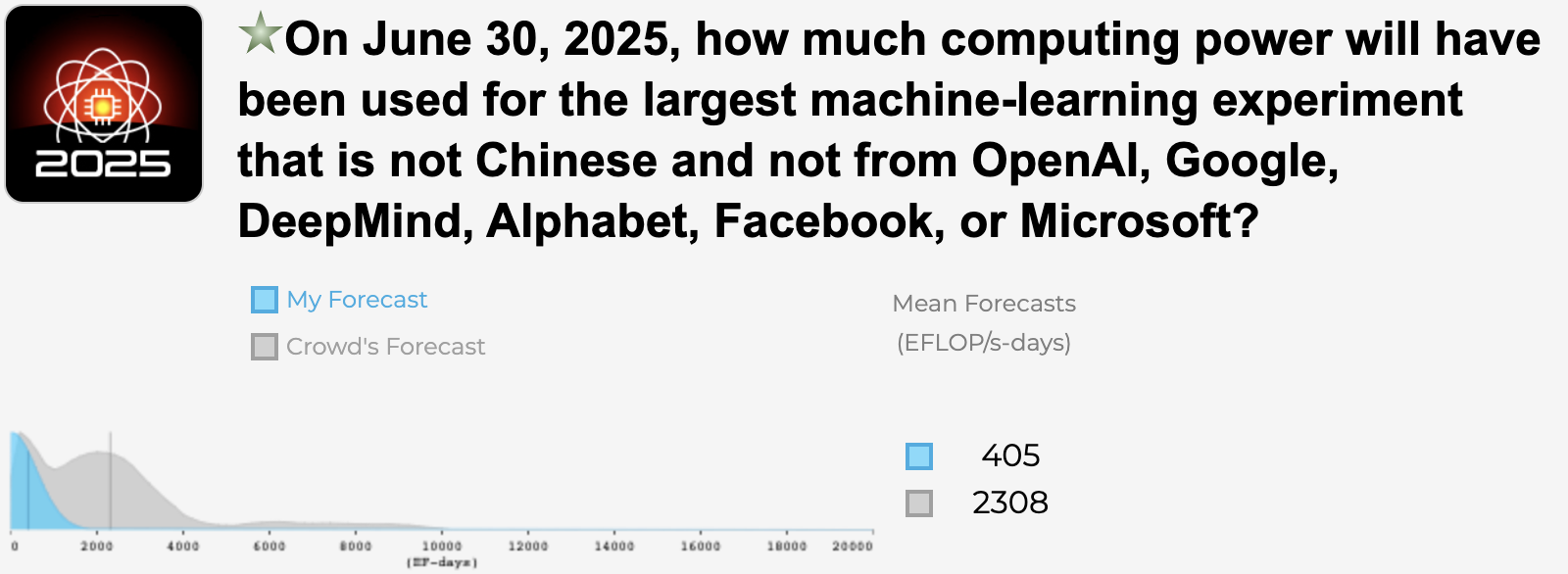
I'm less confident than the crowd that the 3.5 month compute doubling time identified in AI and Compute will hold up (or close), mostly due to this insightful Metaculus comment by krtnu about how companies can't continue to scale up cash investments in experiments without hitting limits soon. Note that I wish I could add a longer right tail to this forecast, but have a bit of a lower mean. I couldn't figure out how to do this with the Hypermind interface.
MATH dataset SOTA
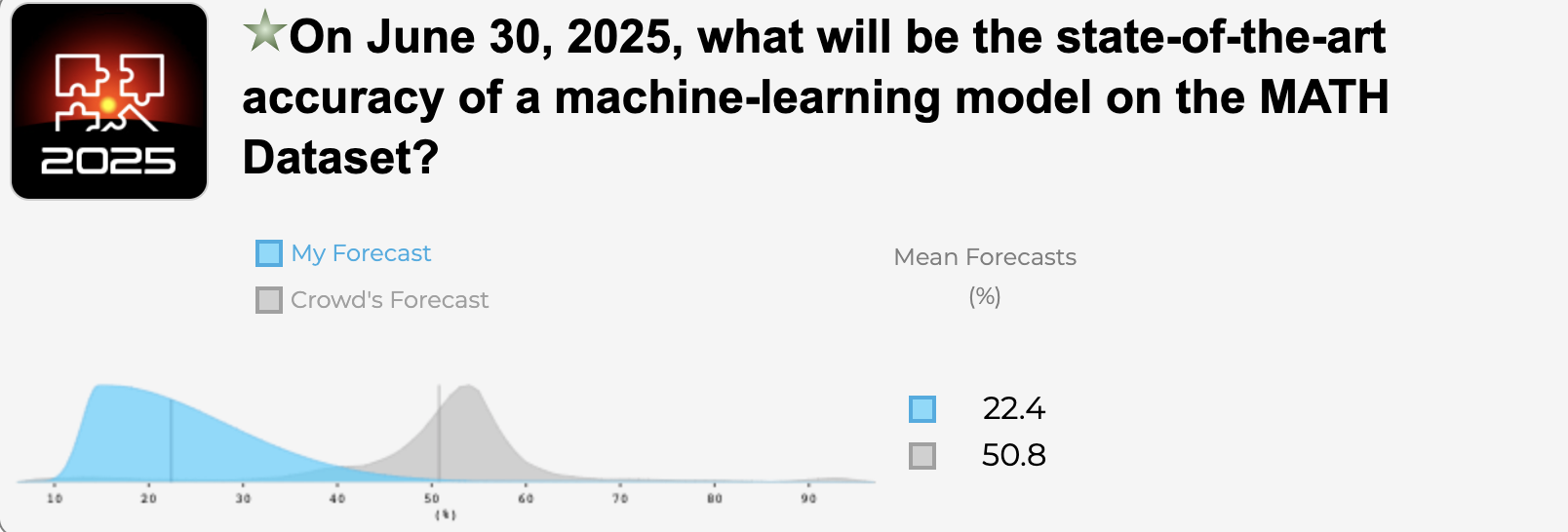
Similar to Jacob Steinhardt (whose group commissioned these questions), I'm skeptical of how much progress the crowd is projecting on MATH by 2025. It seems like an extremely challenging task. The current SOTA is 6.9%.
Massive Multitask dataset SOTA
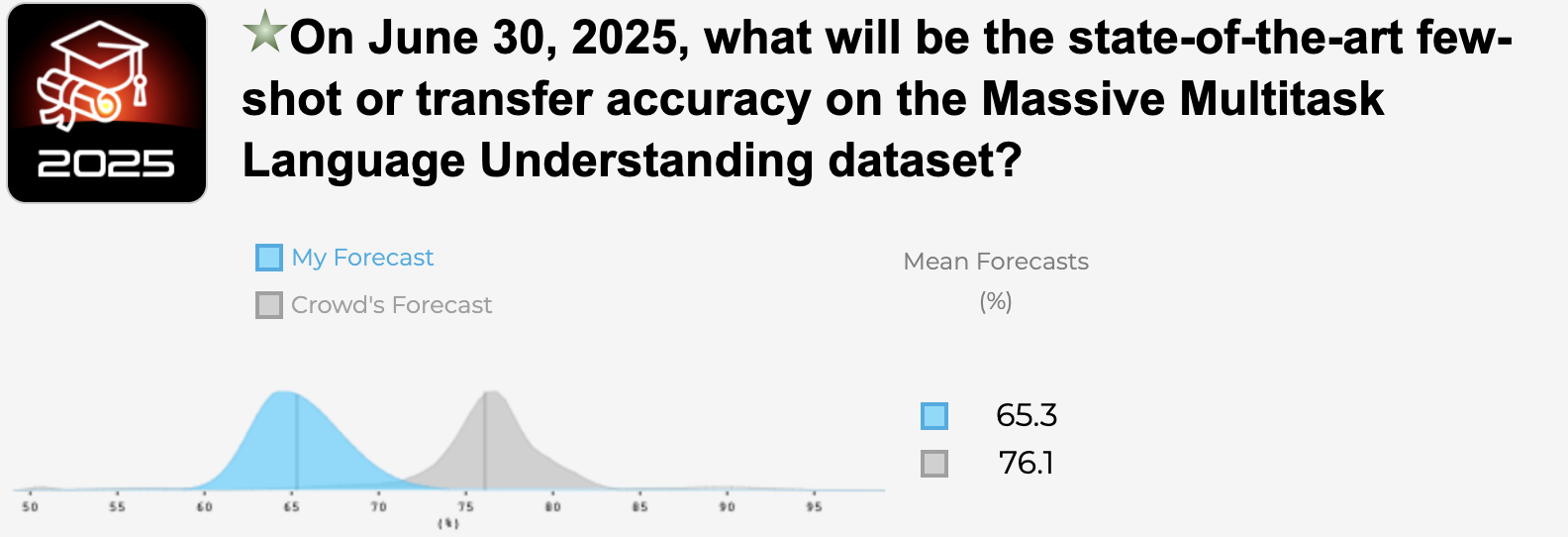
While the difference isn't as dramatic, I'm also more pessimistic than the crowd about advancements on the Massive Multitask Language Understanding. The current SOTA is 49.8%.
Reflections
My forecasts relative to the crowd
I’m predicting slower progress than the crowd on all questions about progress speed (which are all but US vs. China), similar to Jacob Steinhardt. I think he overrates how much he should defer to the crowd here, given that the questions are open for anyone to predict on AFAICT.
What does this generally mean re: AI timelines? It’s plausible that I’m more uncertain and/or generally expect slower progress than the median EA/rationalist focused on AI risk. I'm hoping to do a more extensive project where I attempt to form my overall views on Transformative AI timelines soon.
Impact of this and future tournaments
I'm generally excited about there being more AI forecasting tournaments with non-trivial prize pools, and am thankful for the effort put in to run these.
However, I thought this tournament was a good illustration of some areas of crowd forecasting I'm excited for there to be work on improving. For ideas about how to help with these issues, see my draft outline on bottlenecks to more impactful crowd forecasting.
Collaboration and reasoning transparency
There is very little discussion and transparency of forecasters’ reasoning on the question pages. Ideally the tournament would encourage collaboration and reasoning transparency, but at present it’s discouraged because of the zero-sum prize pool.
Jacob mentioned that improvements on this axis would be helpful in his blog post:
- “We could potentially get around this issue by interrogating forecasters' actual reasoning, rather than just the final output.”
- “This still just seems wild to me and I'm really curious how the forecasters are reasoning about this.”
I linked to my reasoning in a comment when making all my forecasts, in an effort to help with this.
Impactful question creation
I’m unsure about whether we could create questions that don’t feel as much like one of the main skills being tested is forming continuous distributions to extrapolate trends. It seems like there's a large space of exploration for techniques we could try to create impactful questions; e.g. we could have someone with short and long AI timelines debate and create questions on the most important areas of disagreement. Some notes:
- I felt similarly about the Metaculus/OpenPhil AI progress tournament.
- I wonder if MTAIR could be useful in identifying cruxes that are particularly important for prediction.
Full-time AI forecasters
How AI will progress seems like one of the most important questions for cause priortization. Beyond simple timelines, forecastable questions about how the world will progress as AI gets more and more powerful seem to plausibly be at the crux of disagreements between people who have different opinions on the value of various approaches to reducing AI risk.
I think there should be way more full-time AI forecasters: experts in predicting how AI will go (the main current organization I know of is AI Impacts). The impact of more full-time AI forecasters could be much larger than that of the current tournaments. Creating the important questions, improving our predictions on them (including collaboration and reasoning transparency), and communicating the implications of forecasts all seem like important areas for much more further work.
See also:
- AI Timelines: Where the Arguments, and the "Experts," Stand: 'That is, it's not clear to me what a natural "institutional home" for expertise on transformative AI forecasting, and the "most important century," would look like. But it seems fair to say there aren't large, robust institutions dedicated to this sort of question today.'
- Updates and Lessons from AI forecasting: 'Every organization that's serious about the future should have a resident or consultant forecaster'
Technical complaint
Hypermind really needs to allow forecasts with larger standard deviations. The limits feel arbitrary, vary across questions and make my and the crowd’s forecasts much narrower than they ought to be for no real reason. All of my forecasts above would have much longer tails if allowed. Running a contest with prize money and not being able to gather real information about how long people's forecasted tails are seems like such a waste.
More details
See more details about my forecasts and comment inline on this Google Doc. You can also view and comment on LessWrong.